Multivariate basin or play analysis
"For experience, when it wanders in its own track, is mere groping in the dark, and confounds men rather than instructs them. But when it shall proceed in accordance with a fixed law, in regular order, and without interruption, then may better things be hoped for of knowledge"
Francis Bacon, "The New Organon", (1620).
Geological Petroleum System Analysis (PSA) is based on a fixed model in which the inputs are subjective judgments based on experience. However that experience is not usually tabulated or analyzed formally. In a multivariate analysis there are a number of factors that are included if the statistical analysis of a "learning set" shows a significant correlation with the prospectivity. Therefore the model is not fixed beforehand. Here are a few examples of the multivariate approach.
Hydrocarbons versus Basin Volume
Using a learning set of 67 basins worldwide, a linear regression was calculated of HC volume on Basin volume. As expected, there is a statistically significant correlation, which is also intuitively expected. First of all, a larger basin will have more reservoir rock, and also more chances of containing a source rock. Moreover, a large basin volume will tend to be associated with a greater maximum depth, which in turn helps maturity of sourcerocks.However, only 18% of the the variation in HC volume is explained. The conclusion is that prediction on this variable alone is hardly worth the effort.
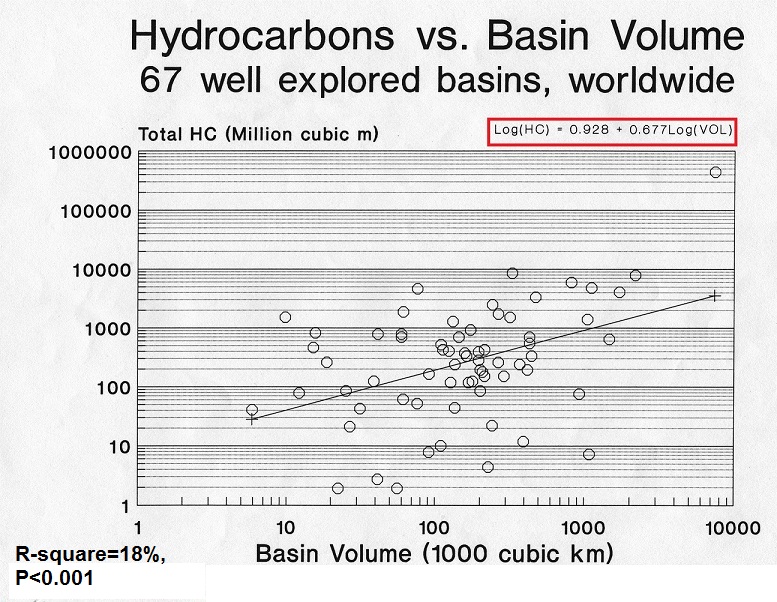
A similar analysis based on only the surface area of basins arrives at 12% explained variance.
HC-bearing versus two variables: Basin Volume and Maximum Depth
This displays a plot of basins in a 2-D space: logarithm of Volume and Logarithm of maximum depth. The discriminant analysis showed a significant discrimination between dry and HC bearing, except that the dry basins overlap the HC bearing ones in the SW corner of the graph:
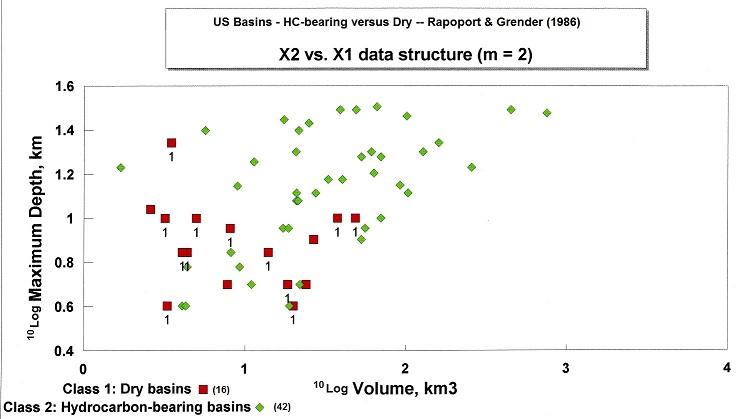
A more complete analysis
The multivariate basin analysis goes through the following steps:
- Gathering a learning set of basins where exploration is advanced ("mature" basins).
- Deciding on the factors, which are in most cases proxies for more detailed geological variables.
- Measuring the variables in the learning set basins.
- Carrying out a multivariate regression and discriminant analysis.
- Discarding the non-significant proxies.
- Collecting information on prior probabilities for all basins, thus a larger set than the learning set.
- Construct a bayesian monte carlo simulation program to be used for estimating prospectivity for a non-mature basin.
In this study the learning set contained 90 basins, 63 with oil, 4 with only gas and 23 dry.
The set is a biased sample of all basins because of difficulties in obtaining data. Therefore the frequencies of oil, gas or dry in the learning set can not be taken to give prior probabilities.
The priors for Hydrocarbons (HC) in basins were estimated as follows from a total of 434, of which 29 not explored (hence unknown HC content). Remainder, 405 basins to be used.
| Classification | Number of basins | Prior probability |
|---|---|---|
| Dry basins | 172 | P[HC]=0.537 |
| Non-associated gas only | 25 | P[OIL|HC]=0.794 |
| Oil only, no NAG | 34 | P[NAG|OIL]=0.54 |
| Non-associated gas | 153 | P[NAG|HC]=0.584 |
Then a discriminant analysis was carried out with 8 geological variables that could be estimated in all the learning set basins. Four of these proved to be significant in classifying basins into dry or oil or gas-only. The parameters can be roughly related to factors of fulfillment, and hence "proxy variables".
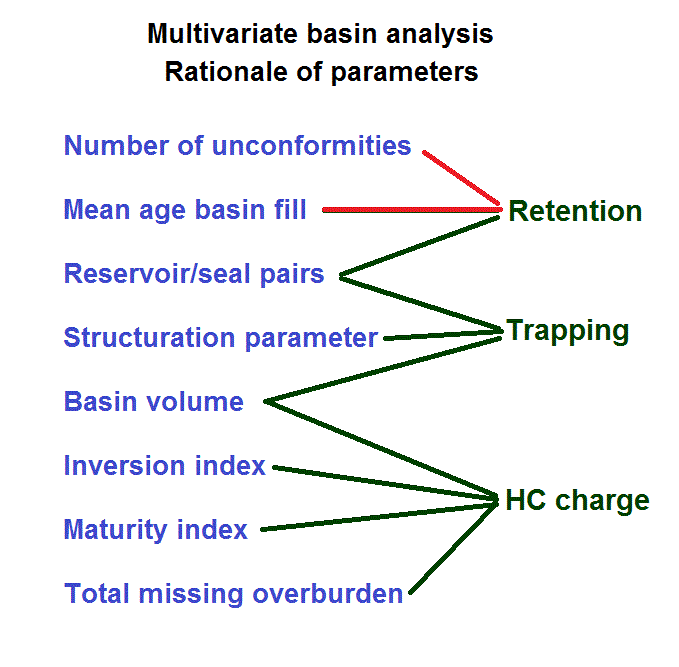
In the above scheme, red lines indicate negative correlation, green positive. For the regression on volume of HC, the R-square varied from 35 for oil to 47% for total gas.
It stands to reason that in this analysis it transpired that basin volume is not a significant factor for discrimination, though for the volume of HC it is. The discrimination on the basis of the four variables takes place in 4-dimensional space, which we can only show in two dimensions with the help of a "non-linear mapping" program. This gives the least-distorted projection of points in 4-D onto a 2-D map, of which the scale is irrelevant.
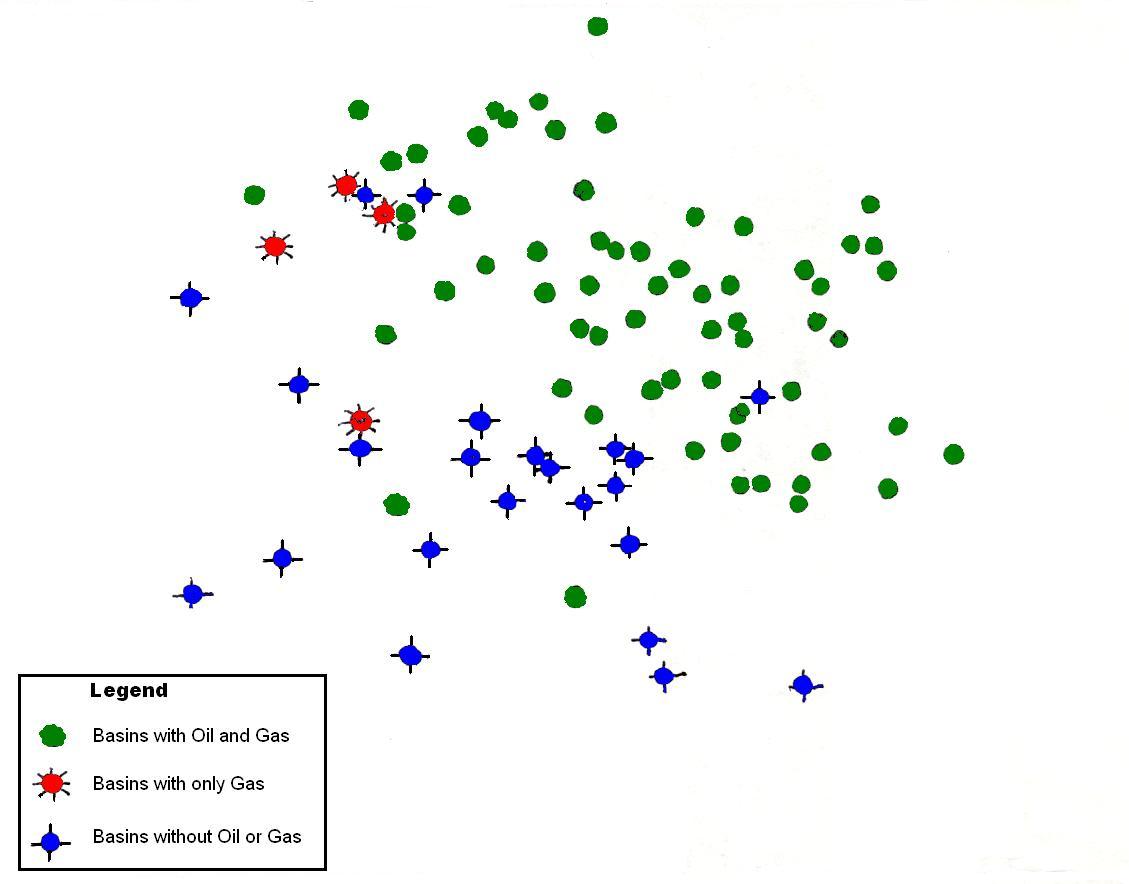
The separation is very nice. Also interesting: the non-associated gas basins from a special group in the center-left of the cloud.
We can conclude from this research that:
- Discrimination is sensitive to a set of variables that is different from those that determine HC-volume, or at least the significances are different.
- Combination of bayesian discriminant analysis and multiple regression can be used to obtain a predictive distribution of HC volumes and chances.
What has been described above for sedimentary basins is, with some modifications, also applicable to plays.
There has been much hope that "Basin Classification" would be very helpful in estimating basin resources. Unfortunately, the variety of petroleum systems within basins is often greater than the inter-basin variance. Thus general tectonic classification is less predictive than one might hope for (Bally et al., 1980, Klemme, 1971, Halbouty, 1970). However, it is interesting to read the discussion about this in a document "not-needed-basin-calssification" on the Scribd site on the internet, by ONGC, India.