Discriminant Analysis
Principles
A geologist has a number of N objects. Each object has several characteristics X1, X2, X3, ...Xm. These are m numerical characteristics. The objects come from two distinct and mutually exclusive sets: class 1 with N1 objects and class 2 with N2 objects (N1 + N2 = N) , for instance, sedimentary rocks and igneous rocks. This set of N objects is called the Learning Set. The characteristics (Xi) might be content of feldspar, quartz, density, hardness, etc. The problem is to use these X-variables to classify a new object.
Discriminant analysis is a multivariate technique that looks for a linear combination of the X-variables that best separates the two classes:
The linear combination of the Xi leads to the so-called Discriminant Score. If the discrimination is successful, the distribution of scores for class 1 will be shifted with respect of class 2. If not successful, such distributions of D will more or less coincide. For a perfect discrimination the plot of data points in m-dimensional space may look like this, if projected onto a two-dimensional space:
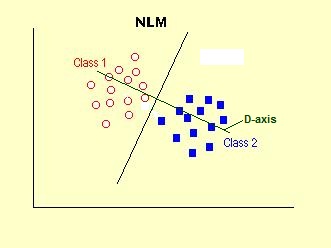
The axis on which points are projected is called the D-axis. The two axis of this figure have no particular meaning. If we had only two variables, the axis would represent x1 and x2. Note that in this ideal example there is no overlap of projected points on the D-axis The analysis is arranged in such a way that the best separation is at D=0. A perfect separation makes class 1 D-scores negative and class 2 D-scores positive. If the separation is not perfect it may happen that some of the objects of class 2 have negative D-scores and/or some Class 1 D-scores turn out to be positive. Such objects are "misclassifications". By applying the classification rule to the Learning Set, a "mis-classification percentage" can be calculated. Roughly speaking, an unsuccessful discrimination will lead to a 50% mis-classification percentage. Successful discrimination usually has less than 25% mis-classification. But this scale from 0 to 50% is a rather arbitrary scale and the value may have arisen by chance. To test the statistical significance of the discrimination rule, we can make a two-sample test of the D-scores of class 1 and class 2, assuming that these are normally distributed (t-test). It is also possible to use a non-parametric test, such as the Mann-Whitney two-sample test on the D-scores as well as a test based on the data structure (Join test).
In practice, overlap of classes is common and raises the question if we can say something about the "probability of class membership". That can be done by a bayesian method, of which we discuss the relatively simple case of two classes: Bayesian discriminant analysis.